Deployando microsserviços com RabbitMQ e MongoDB no Kubernetes
Uma dos pontos fortes do Kubernetes é que ele nos empodera como desenvolvedores para que possamos, de forma simples, levantar, configurar e monitorar sistemas em produção, liberando nossos colegas de infra para que façam menos trabalho operacional no nível das aplicações e possam focar na infraestrutura como um todo.
Nesse tutorial vamos deployar sistemas usando uma arquitetura de microsserviços onde os mesmas se comunicam usando o RabbitMQ como message broker e persistem os dados no MongoDB. Veremos também como criar cronjobs e como armazenar de forma correta informações sensíveis (como senhas) no Kubernetes.
Pré-requisitos
Não é obrigatório, mas idealmente você primeiro deveria seguir meu tutorial anterior onde mostro como deployar sua primeira aplicação com Kubernetes.
Para esse laboratório você precisará de:
Verifique se o Minikube está rodando corretamente usando o comando minikube status. Em seguida mude o contexto do kubectl para o Minikube pelo comando kubectl config set-context minikube. Por fim inicialize o Helm no cluster:
helm init --history-max 200
# Creating /home/eduardo/.helm
# Creating /home/eduardo/.helm/repository
# Creating /home/eduardo/.helm/repository/cache
# Creating /home/eduardo/.helm/repository/local
# Creating /home/eduardo/.helm/plugins
# Creating /home/eduardo/.helm/starters
# Creating /home/eduardo/.helm/cache/archive
# Creating /home/eduardo/.helm/repository/repositories.yaml
# Adding stable repo with URL: https://kubernetes-charts.storage.googleapis.com
# Adding local repo with URL: http://127.0.0.1:8879/charts
# $HELM_HOME has been configured at /home/eduardo/.helm.
#
# Tiller (the Helm server-side component) has been installed into your Kubernetes Cluster.
#
# Please note: by default, Tiller is deployed with an insecure 'allow unauthenticated users' policy.
# To prevent this, run `helm init` with the --tiller-tls-verify flag.
# For more information on securing your installation see: https://docs.helm.sh/using_helm/#securing-your-helm-installation
O comando acima instala o Tiller em nosso cluster. Esse componente é responsável por lidar com todos os pacotes instalados no Kubernetes através do Helm. A flag --max-history é recomendada para evitar guardar um histórico ilimitado de configurações de pacotes instalados pelo Helm, o que pode ocupar bastante espaço em disco.
Antes de usar o Helm para instalar dependências, é importante aguardar o Tiller (serviço do Helm que roda no cluster) atingir o status Running. Para ver o status você pode usar o comando abaixo:
kubectl get pod --selector="name=tiller" -n kube-system
# NAME READY STATUS RESTARTS AGE
# tiller-deploy-69d5cd79bb-lhrcs 1/1 Running 0 113s
O que é o Helm?
Helm é uma espécie de gerenciador de pacotes pro Kubernetes. Bancos de dados são um exemplo clássico de aplicação que sempre precisamos instalar, e no fim das contas o que muda entre uma instalação e outra são só algumas configurações. O Helm resolve exatamente esse problema, permitindo que instalemos esses serviços num cluster Kubernetes mudando somente as configurações que julgarmos relevantes, como espaço em disco, usuário, senha etc.
Levantando o RabbitMQ
Com o Helm instalado e o Tiller rodando em nosso cluster, já temos condições de instalar o RabbitMQ usando seu chart oficial:
helm install stable/rabbitmq \
--name my-rabbitmq \
--set="rabbitmq.username=guest" \
--set="rabbitmq.password=guest" \
--set="persistence.size=1Gi"
# NAME: my-rabbitmq
# LAST DEPLOYED: Tue Jun 18 21:40:10 2019
# NAMESPACE: default
# STATUS: DEPLOYED
#
# RESOURCES:
# ==> v1/ConfigMap
# NAME DATA AGE
# my-rabbitmq-config 2 1s
#
# ==> v1/Pod(related)
# NAME READY STATUS RESTARTS AGE
# my-rabbitmq-0 0/1 Pending 0 1s
#
# ==> v1/Role
# NAME AGE
# my-rabbitmq-endpoint-reader 1s
#
# ==> v1/RoleBinding
# NAME AGE
# my-rabbitmq-endpoint-reader 1s
#
# ==> v1/Secret
# NAME TYPE DATA AGE
# my-rabbitmq Opaque 2 1s
#
# ==> v1/Service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# my-rabbitmq ClusterIP 10.103.148.52 <none> 4369/TCP,5672/TCP,25672/TCP,15672/TCP 1s
# my-rabbitmq-headless ClusterIP None <none> 4369/TCP,5672/TCP,25672/TCP,15672/TCP 1s
#
# ==> v1/ServiceAccount
# NAME SECRETS AGE
# my-rabbitmq 1 1s
#
# ==> v1beta2/StatefulSet
# NAME READY AGE
# my-rabbitmq 0/1 1s
#
#
# NOTES:
#
# ** Please be patient while the chart is being deployed **
#
# Credentials:
#
# Username : guest
# echo "Password : $(kubectl get secret --namespace default my-rabbitmq -o jsonpath="{.data.rabbitmq-password}" | base64 --decode)"
# echo "ErLang Cookie : $(kubectl get secret --namespace default my-rabbitmq -o jsonpath="{.data.rabbitmq-erlang-cookie}" | base64 --decode)"
#
# RabbitMQ can be accessed within the cluster on port at my-rabbitmq.default.svc.cluster.local
#
# To access for outside the cluster, perform the following steps:
#
# To Access the RabbitMQ AMQP port:
#
# kubectl port-forward --namespace default svc/my-rabbitmq 5672:5672
# echo "URL : amqp://127.0.0.1:5672/"
#
# To Access the RabbitMQ Management interface:
#
# kubectl port-forward --namespace default svc/my-rabbitmq 15672:15672
# echo "URL : http://127.0.0.1:15672/"
No exemplo acima três parâmetros foram passados na instalação do RabbitMQ: username, password e persistence.size. Para uma lista completa de parâmetros você pode consultar a documentação desse chart.
O output do comando dá diversas dicas interessantes, entre elas como podemos acessar o RabbitMQ, como podemos resgatar a senha etc. No caso específico da senha, ela fica armazenada em um secret, assunto que abordarei mais tarde nesse tutorial.
Para acessarmos o painel de administração, podemos fazer um redirecionamento de portas do serviço que o Helm criou. Lembrando que a porta padrão do painel de administração do RabbitMQ é 15672:
kubectl port-forward svc/my-rabbitmq 15672:15672
Agora podemos acessar http://localhost:15672 no nosso navegador e fazer login com usuário/senha guest/guest, conforme parâmetros passados na instalação pelo Helm.
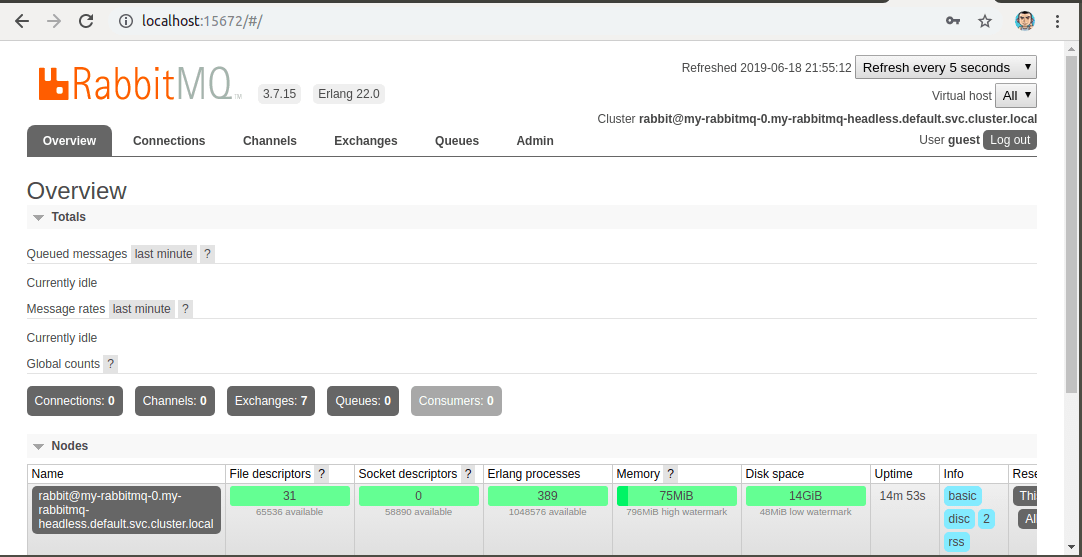
Aproveitando que estamos com o RabbitMQ aberto, vamos criar três filas que usaremos mais a frente. Pela minha falta de criatividade, vou sugerir os nomes queue-1, queue-2 e queue-3. No painel de administração do RabbitMQ navegue até a aba Queues, e em seguida na seção Add a new queue preencha o campo Name com queue-1 e confira se a opção Durability está definida como Durable, por fim clique em Add queue. Faça o mesmo para queue-2 e queue-3.
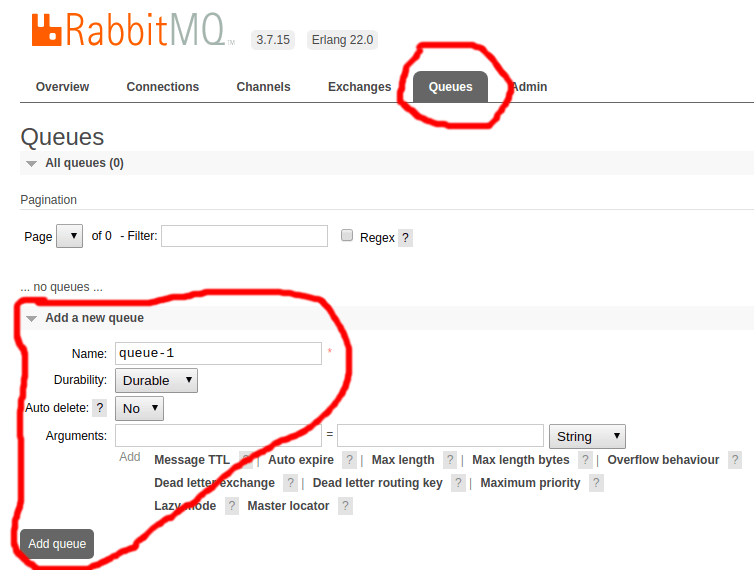
As filas devem aparecer imediatamente no painel:
Levantando o MongoDB
Assim como fizemos com o RabbitMQ, também instalaremos o MongoDB usando o chart oficial do Helm:
helm install stable/mongodb \
--name="my-mongo" \
--set="mongodbRootPassword=root-password" \
--set="mongodbUsername=dummy" \
--set="mongodbPassword=spam" \
--set="mongodbDatabase=my-database" \
--set="persistence.size=1Gi"
# NAME: my-mongo
# E0618 22:04:22.887538 12573 portforward.go:372] error copying from remote stream to local connection: readfrom tcp4 127.0.0.1:41113->127.0.0.1:51308: write tcp4 127.0.0.1:41113->127.0.0.1:51308: write: broken pipe
# LAST DEPLOYED: Tue Jun 18 22:04:22 2019
# NAMESPACE: default
# STATUS: DEPLOYED
#
# RESOURCES:
# ==> v1/PersistentVolumeClaim
# NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
# my-mongo-mongodb Bound pvc-2c8cd9b9-922e-11e9-b2d1-080027847a95 1Gi RWO standard 0s
#
# ==> v1/Pod(related)
# NAME READY STATUS RESTARTS AGE
# my-mongo-mongodb-58f4d6d9d-f94kd 0/1 Pending 0 0s
#
# ==> v1/Secret
# NAME TYPE DATA AGE
# my-mongo-mongodb Opaque 1 0s
#
# ==> v1/Service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# my-mongo-mongodb ClusterIP 10.107.5.198 <none> 27017/TCP 0s
#
# ==> v1beta1/Deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# my-mongo-mongodb 0/1 1 0 0s
#
#
# NOTES:
#
#
# ** Please be patient while the chart is being deployed **
#
# MongoDB can be accessed via port 27017 on the following DNS name from within your cluster:
#
# my-mongo-mongodb.default.svc.cluster.local
#
# To get the root password run:
#
# export MONGODB_ROOT_PASSWORD=$(kubectl get secret --namespace default my-mongo-mongodb -o jsonpath="{.data.mongodb-root-password}" | base64 --decode)
#
# To connect to your database run the following command:
#
# kubectl run --namespace default my-mongo-mongodb-client --rm --tty -i --restart='Never' --image bitnami/mongodb --command -- mongo admin --host my-mongo-mongodb --authenticationDatabase admin -u root -p $MONGODB_ROOT_PASSWORD
#
# To connect to your database from outside the cluster execute the following commands:
#
# kubectl port-forward --namespace default svc/my-mongo-mongodb 27017:27017 &
# mongo --host 127.0.0.1 --authenticationDatabase admin -p $MONGODB_ROOT_PASSWORD
Da mesma forma que na instalação do RabbitMQ, o output do comando acima exibirá diversas informações úteis (super recomendo que as leia).
O MongoDB pode levar alguns minutos para ficar acessível. Para saber o status do Pod você pode usar o seguinte comando:
kubectl get pods --selector="app=mongodb"
# NAME READY STATUS RESTARTS AGE
# my-mongo-mongodb-588f6bdcc5-pkzbb 1/1 Running 0 4m29s
Vamos acessar o banco de dados localmente pra garantir que tudo está funcionando como esperado. Primeiro temos de redirecionar a porta 27017 do serviço criado:
kubectl port-forward svc/my-mongo-mongodb 27017:27017
Em seguida conectamos no banco (é necessário ter o client do MongoDB instalado localmente):
mongo localhost:27017/my-database -u dummy -p spam
# connecting to: mongodb://localhost:27017/my-database
# MongoDB server version: 4.0.10
>
Pra ter certeza que nosso usuário do banco tem permissão de criar e remover documentos, vamos fazer algumas queries no console do Mongo:
> db.collections.aDummyCollection.insert({ foo: 'bar' })
# WriteResult({ "nInserted" : 1 })
> db.collections.aDummyCollection.find()
# { "_id" : ObjectId("5d0c2addcaf167b3b789e78d"), "foo" : "bar" }
> db.collections.aDummyCollection.deleteOne({ _id: ObjectId('5d0c2addcaf167b3b789e78d') })
# { "acknowledged" : true, "deletedCount" : 1 }
Se você teve resultados semelhantes aos de cima, então tudo deve ter funcionando corretamente. Se não funcionou, além das credenciais de acesso você pode verificar se o client do Mongo instalado na sua máquina é compatível com a versão do Mongo que está rodando no seu cluster Kubernetes.
Levantando os serviços intermediários
Para simular serviços se comunicando através de filas, vamos usar a imagem ematos/bypass (https://github.com/eduardo-matos/bypass). Essa imagem joga mensagens de uma fila de origem para uma fila de destino, além de permitir uma configuração de tempo mínimo e máximo para processamento da mensagem e taxa de erros (a mensagem é enviada de volta pra fila de origem caso ocorra algum erro). Vamos criar o deployment desse serviço:
apiVersion: apps/v1
kind: Deployment
metadata:
name: microservice-1
spec:
replicas: 1
selector:
matchLabels:
app: microservice-1
template:
metadata:
labels:
app: microservice-1
spec:
containers:
- name: my-container
image: ematos/bypass
imagePullPolicy: Always
env:
- name: RABBITMQ_SOURCE_QUEUE_NAME
value: queue-1
- name: RABBITMQ_DESTINATION_QUEUE_NAME
value: queue-2
- name: RABBITMQ_HOST
value: my-rabbitmq
- name: RABBITMQ_PORT
value: "5672"
- name: RABBITMQ_USER
value: guest
- name: RABBITMQ_PASS
value: guest
- name: APP_MIN_DURATION_IN_MILLISECONDS
value: "0"
- name: APP_MAX_DURATION_IN_MILLISECONDS
value: "1000"
- name: APP_ERROR_RATE
value: "0.1"
Gostaria de chamar a atenção pro fato das variáveis de ambiente numéricas estarem entre aspas. Isso é obrigatório pra evitar erro de parsing do yaml ao deployar o serviço. Obrigatoriamente variáveis de ambiente devem ser uma string, e nunca um número.
Pra garantir que tudo está funcionando, primeiro vamos aplicar esse yaml:
kubectl apply -f microservice-1.yaml
# deployment.apps/microservice-1 created
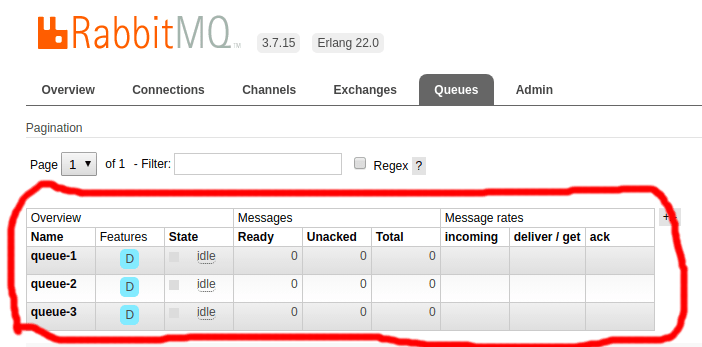
Em seguida vamos adicionar uma mensagem à fila queue-1 e ver se ela aparece na fila queue-2. No painel de administração do RabbitMQ vamos à aba Queues, clicamos em queue-1 para acessar a fila, e na seção Publish message preenchemos o campo Payload com um JSON vazio ({}), daí clicamos em Publish message.
Clicando novamente na aba Queues, se tudo der certo em alguns segundos a fila queue-2 exibirá uma mensagem.
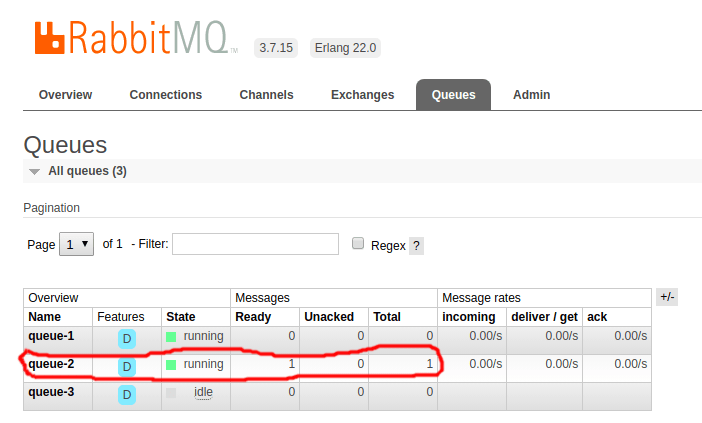
Pra ver a mensagem na fila queue-2, basta acessar essa fila, abrir a seção Get messages e clicar em Get message(s).
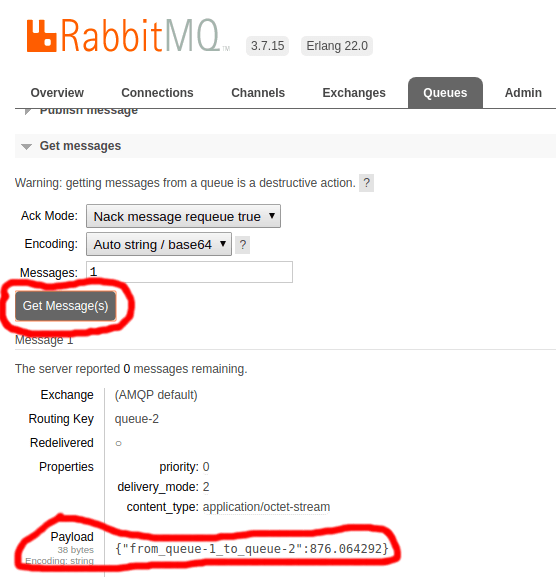
A chave no JSON diz qual a fila de origem, qual a fila de destino, e o tempo (em milissegundos) que a mensagem levou pra ser processada.
Agora vamos criar um novo serviço, dessa vez pra jogar mensagens da fila queue-2 pra fila queue-3:
apiVersion: apps/v1
kind: Deployment
metadata:
name: microservice-2
spec:
replicas: 1
selector:
matchLabels:
app: microservice-2
template:
metadata:
labels:
app: microservice-2
spec:
containers:
- name: my-container
image: ematos/bypass
imagePullPolicy: Always
env:
- name: RABBITMQ_SOURCE_QUEUE_NAME
value: queue-2
- name: RABBITMQ_DESTINATION_QUEUE_NAME
value: queue-3
- name: RABBITMQ_HOST
value: my-rabbitmq
- name: RABBITMQ_PORT
value: "5672"
- name: RABBITMQ_USER
value: guest
- name: RABBITMQ_PASS
value: guest
- name: APP_MIN_DURATION_IN_MILLISECONDS
value: "100"
- name: APP_MAX_DURATION_IN_MILLISECONDS
value: "700"
- name: APP_ERROR_RATE
value: "0.4"
Em relação ao microservice-1, além do nome e label mudei as filas de origem e destino (RABBITMQ_SOURCE_QUEUE_NAME e RABBITMQ_DESTINATION_QUEUE_NAME), os valores mínimo e máximo para tempo de processamento da mensagem (APP_MIN_DURATION_IN_MILLISECONDS e APP_MAX_DURATION_IN_MILLISECONDS) e a taxa de erros (APP_ERROR_RATE). Por fim podemos aplicar essa nova configuração:
kubectl apply -f microservice-2.yaml
# deployment.apps/microservice-2 created
Acessando o painel administrativo do RabbitMQ, em poucos segundos a fila queue-2 deve aparecer zerada, e a fila queue-3 deve aparecer com uma mensagem.
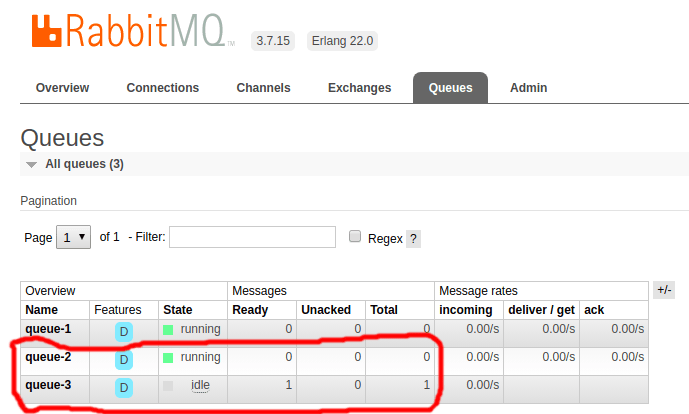
Pegando essa mensagem na fila queue-3, podemos ver uma nova chave no JSON.
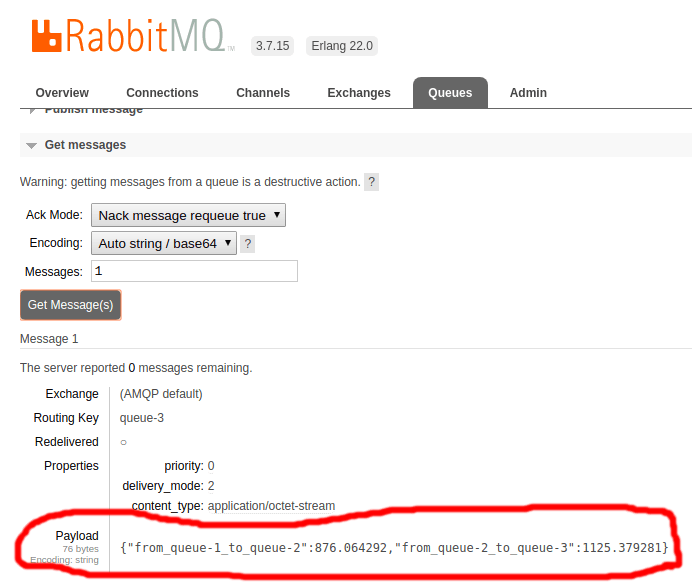
Existe uma chance de 40% de ter dado erro ao processar a mensagem (devido à variável APP_ERRRO_RATE ser igual a 0.4):
kubectl logs -l "app=microservice-2"
# I, [2019-06-21T03:28:03.305874 #1] INFO -- : [*] Awaiting for messages
# I, [2019-06-21T03:28:03.725884 #1] INFO -- : Oops, some error occurred! Sending message back to source queue
# I, [2019-06-21T03:28:04.862051 #1] INFO -- : Message processed in 1125.4 milliseconds
Você pode inserir diversas mensagens na fila queue-1 e em alguns segundos elas apareceção na fila queue-3.
Levantando o Persister
Agora que temos as aplicações microservice-1 e microservice-2 movendo mensagens entre as filas no RabbitMQ, falta levantar uma aplicação que salva as mensagens da fila queue-3 no MongoDB. Para isso usaremos a imagem ematos/persister (https://github.com/eduardo-matos/persister). A configuração do yaml fica assim:
apiVersion: apps/v1
kind: Deployment
metadata:
name: microservice-persister
spec:
replicas: 1
selector:
matchLabels:
app: microservice-persister
template:
metadata:
labels:
app: microservice-persister
spec:
containers:
- name: my-container
image: ematos/persister
imagePullPolicy: Always
env:
- name: RABBITMQ_SOURCE_QUEUE_NAME
value: queue-3
- name: RABBITMQ_HOST
value: my-rabbitmq
- name: RABBITMQ_PORT
value: "5672"
- name: RABBITMQ_USER
value: guest
- name: RABBITMQ_PASS
value: guest
- name: RABBITMQ_VHOST
value: "/"
- name: APP_CONCURRENCY
value: "1"
- name: APP_MIN_DURATION_IN_MILLISECONDS
value: "50"
- name: APP_MAX_DURATION_IN_MILLISECONDS
value: "800"
- name: APP_ERROR_RATE
value: "0.3"
- name: MONGODB_URL
value: "mongodb://dummy:spam@my-mongo-mongodb:27017"
- name: MONGODB_DATABASE_NAME
value: my-database
- name: MONGODB_COLLECTION_NAME
value: events
Aplicando essa configuração no Kubernetes:
kubectl apply -f microservice-persister.yaml
# deployment.apps/microservice-persister created
Após alguns segundos a aplicação deve estar rodando. Quando isso acontecer podemos consultar os logs pra ver o que aconteceu:
kubectl logs -l app=microservice-persister
# Failed to insert "{"from_queue-1_to_queue-2":876.064292,"from_queue-2_to_queue-3":1125.379281}" Error: A simulated error occurred
# at /app/src/index.js:12:13
# at async /app/src/rabbit.js:18:24
# Inserted Id="5d0ce850bf60a2000fdb778b"
No meu caso ocorreu um erro na primeira tentativa de inserir a mensagem no banco de dados, e na segunda tentativa funcionou corretamente.
Testando o processo de ponta a ponta
Acessando novamente o painel de administração do RabbitMQ (não se esqueça de usar kubectl port-forward) nós podemos adicionar uma mensagem na fila queue-1, e ver se ela realmente vai aparecer no banco de dados. Sugiro que você inicie três terminais. O primeiro exibe os logs do microservice-1, o segundo exibe os logs do microservice-2 e o terceiro exibe os logs do microservice-persister:
# No primeiro terminal
kubectl logs --tail 0 --follow -l app=microservice-1
# No segundo terminal
kubectl logs --tail 0 --follow -l app=microservice-2
# No terceiro terminal
kubectl logs --tail 0 --follow -l app=microservice-persister
Após inserir um JSON vazio como mensagem na fila queue-1, você deve ter um resultado parecido com esse:
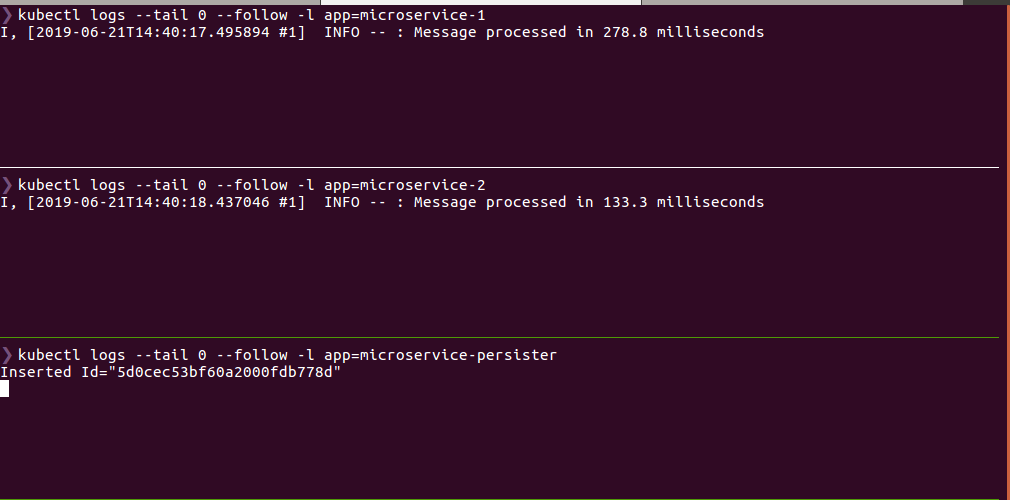
Levantando o Publisher
Inserir mensagens manualmente na fila é tedioso. Pra resolver isso vamos usar o ematos/publisher (https://github.com/eduardo-matos/publisher), um sistema que publica mensagens em uma dada fila do RabbitMQ. Pra tornar essa inserção automática, vamos usar um CronJob no Kubernetes.
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: microservice-publisher
spec:
schedule: "* * * * *" # every minute
concurrencyPolicy: Forbid
suspend: false
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 5
jobTemplate:
spec:
template:
spec:
restartPolicy: Never
containers:
- name: publisher
image: ematos/publisher
imagePullPolicy: Always
env:
- name: RABBITMQ_DESTINATION_QUEUE_NAME
value: "queue-1"
- name: RABBITMQ_HOST
value: "my-rabbitmq"
- name: RABBITMQ_PORT
value: "5672"
- name: RABBITMQ_USER
value: "guest"
- name: RABBITMQ_PASS
value: "guest"
- name: RABBITMQ_VHOST
value: "/"
- name: APP_MIN_MSG_COUNT_TO_PUBLISH
value: "0"
- name: APP_MAX_MSG_COUNT_TO_PUBLISH
value: "100"
No Kubernetes um CronJob dispara um Job de acordo com um dado schedule (spec.schedule), por isso definimos um template de Job em spec.jobTemplate. O formato do schedule é o mesmo que usamos em crontabs.
O campo spec.suspend diz se o cronjob está ativo ou inativo. O uso dsse campo é facultativo, e seu valor padrão é false. Os campos spec.successfulJobsHistoryLimit e spec.failedJobsHistoryLimit informam quantos pods manteremos disponíveis em caso de sucesso e falha respectivamente.
O campo spec.concurrencyPolicy diz como o Kubernetes deve lidar nos casos onde um cronjob for executado enquanto outro ainda estiver rodando. As possíveis opções são Forbid (não permitir rodar um novo cronjob), Allow (permitir rodar o mesmo cronjob simultaneamente) e Replace (matar o cronjob que está rodando antes de iniciar um novo).
O campo spec.jobTemplate.spec.template.spec.restartPolicy é obrigatório, e informa ao Kubernetes o que deve ser feito caso o job falhe. A documentação oficial do Kubernetes explica detalhadamente como essa opção funciona.
Aplicando no Kubernetes:
kubectl apply -f microservice-publisher.yaml
De acordo com as configurações das variáveis de ambiente, essa aplicação vai publicar um número aleatório de mensagens (entre 0 e 100) na fila queue-1.
Após aproximadamente um minuto já podemos visualizar novamente o processo funcionando de ponta a ponta conforme fizemos na seção anterior:
# No primeiro terminal
kubectl logs --tail 0 --follow -l app=microservice-1
# No segundo terminal
kubectl logs --tail 0 --follow -l app=microservice-2
# No terceiro terminal
kubectl logs --tail 0 --follow -l app=microservice-persister
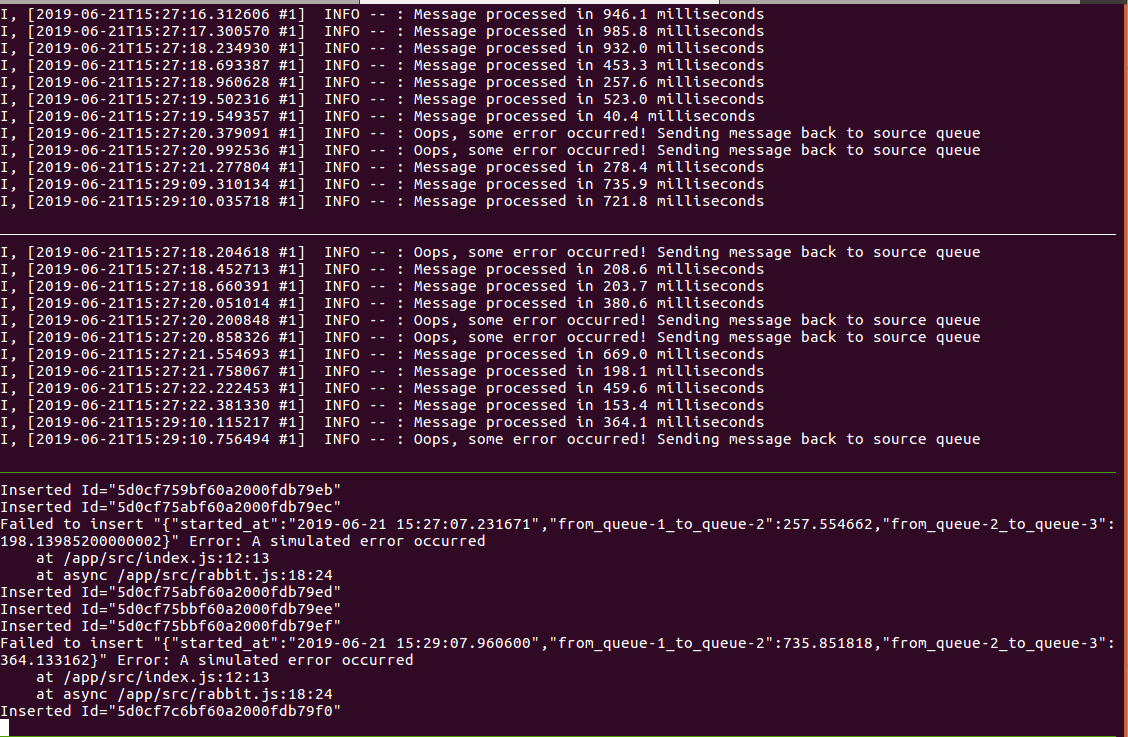
Configurando os secrets
Nesse momento as variáveis de ambiente estão hardcoded no arquivos yaml que criamos, o que significa que dados sensíveis como senha, por exemplo, ficariam visíveis para qualquer pessoa que tivesse acesso ao repositório, o que é uma má prática.
Pra resolver esse problema, vamos usar Secrets no Kubernets. Existem duas formas de criar Secrets: A primeira é usando arquivos yaml com Kind: Secret. A segunda é usando um comando imperativo. Nessa seção mostrarei como fazer usando o comando imperativo.
Primeiro vamos criar um secret para o RabbitMQ:
kubectl create secret generic my-rabbitmq-secret \
--from-literal=host=my-rabbitmq \
--from-literal=port="5672" \
--from-literal=user=guest \
--from-literal=password=guest \
--from-literal=vhost="/"
# secret/my-rabbitmq-secret created
É possível configurar permissão de acesso por usuário no Kubernetes, ou seja, poderíamos permitir que alguns usuários conseguissem visualizar as secrets enquanto outros não, porém essa configuração está fora do escopo desse tutorial.
Podemos visualizar as secrets forçando um output do tipo yaml:
kubectl get secret my-rabbitmq-secret
# NAME TYPE DATA AGE
# my-rabbitmq-secret Opaque 4 1m
kubectl get secret my-rabbitmq-secret -o yaml
# apiVersion: v1
# data:
# host: bXktcmFiYml0bXE=
# password: Z3Vlc3Q=
# port: NTY3Mg==
# user: Z3Vlc3Q=
# kind: Secret
# metadata:
# creationTimestamp: "2019-06-21T15:44:51Z"
# name: my-rabbitmq-secret
# namespace: default
# resourceVersion: "18096"
# selfLink: /api/v1/namespaces/default/secrets/my-rabbitmq-secret
# uid: 81d89a06-943b-11e9-8850-0800277140f5
# type: Opaque
Repare que os valores das secrets estão no formato base64. Para pegar o valor literal podemos fazer a conversão:
echo "bXktcmFiYml0bXE=" | base64 --decode
# my-rabbitmq
echo "Z3Vlc3Q=" | base64 --decode
# guest
echo "NTY3Mg==" | base64 --decode
# 5672
echo "Z3Vlc3Q=" | base64 --decode
# guest
Agora vamos criar as secrets do MongoDB:
kubectl create secret generic my-mongo-secret \
--from-literal=url="mongodb://dummy:spam@my-mongo-mongodb:27017" \
--from-literal=db_name=my-database \
--from-literal=collection_name=events
# secret/my-mongo-secret created
Acessando as secrets do MongoDB:
kubectl get secret my-mongo-secret
# NAME TYPE DATA AGE
# my-mongo-secret Opaque 3 1m
kubectl get secret my-mongo-secret -o yaml
# apiVersion: v1
# data:
# collection_name: ZXZlbnRz
# db_name: bXktZGF0YWJhc2U=
# url: bW9uZ29kYjovL2R1bW15OnNwYW1AbXktbW9uZ28tbW9uZ29kYjoyNzAxNw==
# kind: Secret
# metadata:
# creationTimestamp: "2019-06-21T15:53:56Z"
# name: my-mongo-secret
# namespace: default
# resourceVersion: "18968"
# selfLink: /api/v1/namespaces/default/secrets/my-mongo-secret
# uid: c6b93b19-943c-11e9-8850-0800277140f5
# type: Opaque
Podemos também visualizar todas as secrets:
kubectl get secrets
# NAME TYPE DATA AGE
# default-token-6d6vw kubernetes.io/service-account-token 3 3h
# my-mongo-mongodb Opaque 2 3h
# my-mongo-secret Opaque 3 3m
# my-rabbitmq Opaque 2 3h
# my-rabbitmq-secret Opaque 4 12m
# my-rabbitmq-token-psqff kubernetes.io/service-account-token 3 3h
Aqui vemos não somente as secrets que criamos, como também aquelas que o Helm criou quando instalamos o MongoDB e o RabbitMQ.
Carregando variáveis de ambiente através das secrets
Uma vez que criamos as secrets, temos de voltar em todos os arquivos yaml para substituir os valores hardcoded:
Para o microservice-publisher
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: microservice-publisher
spec:
schedule: "* * * * *" # every minute
concurrencyPolicy: Forbid
suspend: false
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 5
jobTemplate:
spec:
template:
spec:
restartPolicy: Never
containers:
- name: publisher
image: ematos/publisher
imagePullPolicy: Always
env:
- name: RABBITMQ_DESTINATION_QUEUE_NAME
value: "queue-1"
- name: RABBITMQ_HOST
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: host
- name: RABBITMQ_PORT
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: port
- name: RABBITMQ_USER
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: user
- name: RABBITMQ_PASS
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: password
- name: RABBITMQ_VHOST
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: vhost
- name: APP_MIN_MSG_COUNT_TO_PUBLISH
value: "0"
- name: APP_MAX_MSG_COUNT_TO_PUBLISH
value: "100"
Para o microservice-1
apiVersion: apps/v1
kind: Deployment
metadata:
name: microservice-1
spec:
replicas: 1
selector:
matchLabels:
app: microservice-1
template:
metadata:
labels:
app: microservice-1
spec:
containers:
- name: my-container
image: ematos/bypass
imagePullPolicy: Always
env:
- name: RABBITMQ_SOURCE_QUEUE_NAME
value: queue-1
- name: RABBITMQ_DESTINATION_QUEUE_NAME
value: queue-2
- name: RABBITMQ_HOST
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: host
- name: RABBITMQ_PORT
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: port
- name: RABBITMQ_USER
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: user
- name: RABBITMQ_PASS
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: password
- name: APP_MIN_DURATION_IN_MILLISECONDS
value: "0"
- name: APP_MAX_DURATION_IN_MILLISECONDS
value: "1000"
- name: APP_ERROR_RATE
value: "0.1"
Para o microservice-2
apiVersion: apps/v1
kind: Deployment
metadata:
name: microservice-2
spec:
replicas: 1
selector:
matchLabels:
app: microservice-2
template:
metadata:
labels:
app: microservice-2
spec:
containers:
- name: my-container
image: ematos/bypass
imagePullPolicy: Always
env:
- name: RABBITMQ_SOURCE_QUEUE_NAME
value: queue-2
- name: RABBITMQ_DESTINATION_QUEUE_NAME
value: queue-3
- name: RABBITMQ_HOST
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: host
- name: RABBITMQ_PORT
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: port
- name: RABBITMQ_USER
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: user
- name: RABBITMQ_PASS
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: password
- name: APP_MIN_DURATION_IN_MILLISECONDS
value: "100"
- name: APP_MAX_DURATION_IN_MILLISECONDS
value: "700"
- name: APP_ERROR_RATE
value: "0.4"
Para o microservice-persister
apiVersion: apps/v1
kind: Deployment
metadata:
name: microservice-persister
spec:
replicas: 1
selector:
matchLabels:
app: microservice-persister
template:
metadata:
labels:
app: microservice-persister
spec:
containers:
- name: my-container
image: ematos/persister
imagePullPolicy: Always
env:
- name: RABBITMQ_SOURCE_QUEUE_NAME
value: queue-3
- name: RABBITMQ_HOST
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: host
- name: RABBITMQ_PORT
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: port
- name: RABBITMQ_USER
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: user
- name: RABBITMQ_PASS
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: password
- name: RABBITMQ_VHOST
valueFrom:
secretKeyRef:
name: my-rabbitmq-secret
key: vhost
- name: APP_CONCURRENCY
value: "1"
- name: APP_MIN_DURATION_IN_MILLISECONDS
value: "50"
- name: APP_MAX_DURATION_IN_MILLISECONDS
value: "800"
- name: APP_ERROR_RATE
value: "0.3"
- name: MONGODB_URL
valueFrom:
secretKeyRef:
name: my-mongo-secret
key: url
- name: MONGODB_DATABASE_NAME
valueFrom:
secretKeyRef:
name: my-mongo-secret
key: db_name
- name: MONGODB_COLLECTION_NAME
valueFrom:
secretKeyRef:
name: my-mongo-secret
key: collection_name
Aplicando os arquivos no Kubernetes:
kubectl apply -f microservice-publisher.yaml
# cronjob.batch/microservice-publisher configured
kubectl apply -f microservice-1.yaml
# deployment.apps/microservice-1 configured
kubectl apply -f microservice-2.yaml
# deployment.apps/microservice-2 configured
kubectl apply -f microservice-persister.yaml
# deployment.apps/microservice-persister configured
O Kubernetes finalizará os pods antigos e levantará novos carregando as variáveis de ambiente a partir das secrets. Pra garantir que a aplicação realmente está carregando as variáveis de ambiente a partir das secrets, vamos acessar alguns pods e resgatar valores de variáveis de ambiente:
kubectl get pods
# NAME READY STATUS RESTARTS AGE
# microservice-1-58468f86b-6ps5h 1/1 Running 0 4m
# microservice-2-748d69b4d9-ks6j4 1/1 Running 0 4m
# microservice-persister-68899c498c-m6v5z 1/1 Running 0 44m
# microservice-publisher-1561136100-cvkxl 0/1 Completed 0 2m
# microservice-publisher-1561136160-ngtpd 0/1 Completed 0 1m
# microservice-publisher-1561136220-b9kmp 0/1 Completed 0 12s
# my-mongo-mongodb-6844fb7558-t6gf9 1/1 Running 0 4h
# my-rabbitmq-0 1/1 Running 0 4h
# Semelhante a `docker exec`
kubectl exec -it microservice-persister-68899c498c-m6v5z -- sh -c "echo \$MONGODB_URL"
# mongodb://dummy:spam@my-mongo-mongodb:27017
kubectl exec -it microservice-1-58468f86b-6ps5h -- sh -c "echo \$RABBITMQ_USER"
# guest
kubectl exec -it microservice-2-748d69b4d9-ks6j4 -- sh -c "echo \$RABBITMQ_HOST"
# my-rabbitmq
Exercício 1
Uma vantagem do Kubernetes que já tratei em meu tutorial anterior é a facilidade de escalar aplicações horizontalmente. Nesse exercício você deve configurar a variável APP_MAX_MSG_COUNT_TO_PUBLISH=1000 no microservice-publisher. Isso deve fazer uma das filas começar a encher indefinidamente. Sua missão é alterar a quantidade de réplicas do microservice-1 e/ou microservice-2 e/ou microservice-persister de modo que consigam estabilizar o fluxo de mensagens, ou seja, nenhuma fila deve crescer indefinidamente. O desafio é encontrar o menor número de réplicas que torna isso possível. Boa sorte!
Dica: Se precisar parar o microservice-publisher porque a fila está enchendo muito rápido, mude a opção spec.suspend para false e dê um kubectl apply -f microservice-publisher.yaml.
Exercício 2
No caso do microservice-persister você pode alterar a quantidade de réplicas do deployment e/ou incrementar a variável APP_CONCURRENCY. Qual dos dois traz melhores resultados? Qual consome menos memória e cpu total? (use o comand kubectl top pods -l app=microservice-persister para consultar o consumo de memória e cpu do microservice-persister)
Uma curiosidade
Microsserviços são poliglotas. Os projetos ematos/publisher, ematos/bypass e ematos/persister são escritos em linguagens diferentes um do outro. O primeiro em Python, o segundo em Ruby, e o terceiro em JavaScript.
Do ponto de vista da criação das configurações pro Kubernetes isso ficou transparente. Essa é uma grande vantagem que nos possibilita desenvolver aplicações usando a tecnologia mais apropriada pro problema que precisamos resolver sem criar empecilhos que dificultam o deploy de aplicações.
Conclusão
Nesse tutorial demos um grande salto no Kubernetes. Criamos aplicações stateful (RabbitMQ e MongoDB), conectamos aplicações através de um message broker e criamos um cronjob. Também configuramos as variáveis de ambiente de forma segura usando secrets, e simulamos uma situação real onde tivemos de estabilizar um sistema escalando as aplicações horizontalmente. Com o que vimos aqui nos tornamos capazes de desenvolver sistemas mais desacoplados, poliglotas e escaláveis.
Arquivos do tutorial (incluindo secrets): github.com/eduardo-matos/tutorial-kubernetes-microservices